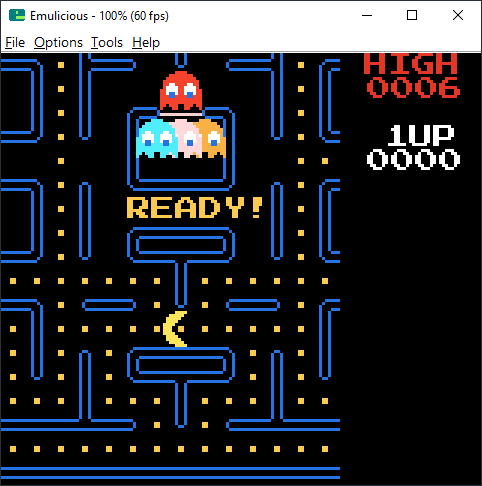
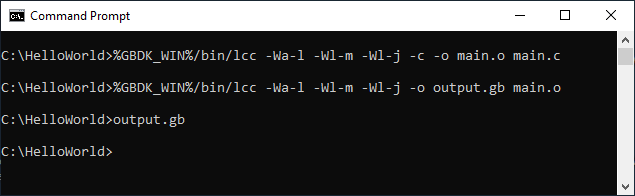
2023 Achievements
Note: leveraging Sega Master System development setup for Nintendo Game Boy is an achievement! |
2024 Objectives
|
Architecture
Software architecture plays crucial role in designing + developing effective software systems. Understanding various architectural styles + patterns available, you can make informed decisions in architectural endeavors to create scalable, maintainable, and reliable software solutions. Architectural styles are high-level strategies that provide an abstract framework for a family of systems e.g. Layered, Event-Driven, and Microservices.
Architect Types
Software architects, solution architects and enterprise architects all play a part in designing, developing and implementing solutions that meet the needs of the business but differ with technical, company and IT focus:
| Software Architect |
A professional who designs and oversees the development of each software system. Ensures that the system meets the needs of the business and is technically feasible. |
| Solution Architect |
A professional who designs and implements solutions that meet needs of the business. They have a deep understanding of both the business and the technology landscapes. |
| Enterprise Architect |
A professional who designs and oversees the overall IT architecture of an organization. Ensures architecture aligned with business strategy and supports goals and objectives. |
Cloud Variants
Cloud computing is becoming common for accessing data and using appliations in web-based environments. Growing demand for technology solutions in this area request need for cloud architects and cloud engineers:
| Cloud Architect |
A professional who deploys cloud-based applications according to business specifications. Architects focus work on the frameworks and infrastructure of cloud-based applications. |
| Cloud Engineer |
A professional who designs, creates and develops cloud-based systems and solutions. Involved in building and testing technical requirements within all these cloud systems. |
Microservices
Microservices have become a game-changer in the quickly changing technological landscape where flexibility, speed and scalability are crucial. Microservices architecture provides a more agile and effective substitute to conventional monolithic techniques and has seen rapidly increasing industry adoption in recent years.
Microservices align seamlessly with DevOps principles, fostering development and operations collaboration for continuous delivery and automation. Microservices architecture also aligns with containerization and orchestration tools like Kubernetes, simplifying the deployment and management of services at scale.
Industry predictions in Microservices expect growth to $1.7b by 2028 as 82% of organizations plan to adopt microservices in the next 3yrs. Microservices are well-suited to leverage emerging technologies such as IoT, edge computing, and blockchain and A.I. has potential to disrupt and innovate in the microservices space.
Future
The Top Tech Skills for 2024 corroborates this as specialization in the cloud computing market is predicted to grow at an annual rate of 18% plus Artificial Intelligence and Machine Learning continue to drive innovations across all industries including using AI in Microservices; AI is becoming an essential part of the microservices ecosystem, enabling businesses to build and maintain large, complex applications more efficiently. It will be interesting to see new innovative ways in which AI may integrate across the Software Engineering spectrum!